











【初心者の方へ】robots.txtとは?書き方とnoindexの違いを教えます。
投稿者:セールスマーケティング部
2018/08/23 15:30
この記事は約6分で読むことができます。
こんにちは!デジタルマーケティング部の片岡です。
今回はrobots.txtの書き方や効果についてご紹介します。
SEOでもよく出てくるけど内容がわかってない方は、改めて勉強し直していきましょう
robots.txtとは

robots.txtとは、クローラーに対して、ディレクトリやページ単位でクロールを制御する際に使うテキストファイルです。
すべての検索エンジンに効果を発揮するわけではないですが、Googleには効果があります。
ではどういうときにrobots.txtを使うのかと言いますと、大きく2つに分かれます。
・クローラーにsitemap.xmlの場所を教えてクロールの促進を行う。
上記の2つを行うことでクローラーが無駄な巡回をせず、効率的なクロールでSEOへの効果を高めてくれます。
robots.txtの確認方法と書き方について

robots.txtってどこで見たらわかるの?と言う方もいらっしゃるのではないでしょうか。
ここでは、robots.txtが設定しているかどうかの確認方法と書き方についてご紹介します。
確認方法についてですが、URLの最後に/robots.txtと入力してもらうだけです。
弊社のフリーセルコーポレートサイトを参考に見ていきましょう。
弊社のサイトで言うとhttps://www.freesale.co.jp/robots.txtこのように検索します。
コーポレートサイトはrobots.txtを設定しているため下記のように出てきます。
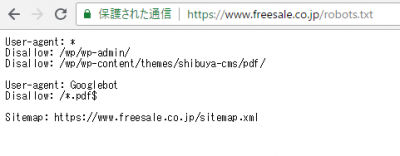
URLの末尾に/robots.txtと入力して、アクセスに成功した場合はきちんと設定されているので、安心してください。
逆にアクセスできない方は、設定ができてない可能性があるので、書き方について見ていきましょう。
では、ここからはrobots.txtの書き方について解説します。
上記のコーポレートサイトの画像からもわかるように大きく3つの言葉を使うことが多いです。
・Disallow:
・Sitemap:
1つずつ意味について解説していきます。
クローラーを指定するUser-agent
User-Agentは、指示を出したいクローラーを決めるために使います。
Googleであれば「Googlebot」、ヤフーのクローラーであれば「Slurp」などです。
検索エンジンごとにクローラーの名前が決まっているので調べてみてください。
すべての検索エンジンを指定したい場合は、「*(アスタリスク)」を記述することをおすすめします。
書き方の例としては以下のような形になるので参考にしてください。
User-agent::*
User-agent: Googlebot
クロールを制御するDisallow
検索エンジンを選んだら、どのような指示を出すのか決めないといけませんね。
その時によく使われるのが、「Disallow」なんです。
意味は、アクセス拒否を表します。
Disallowの後にディレクトリやファイルが入ります。
よくわからない人のために具体的な書き方を紹介します。
Disallow:
→ブロックなし
Disallow:/
→サイト内の全てのページをブロック(TOP配下全てを表します)
Disallow:/○○
→/〇〇/ディレクトリ内すべてブロック
Disallow:/〇〇/××.html
→〇〇ディレクトリ内の××.htmlのページのみブロック
理解できましたでしょうか?
アクセスを拒否したいディレクトリとファイルを書いておけば良いということになります。
複数ページある場合は、複数行にわたって書いてくださいね。
sitemapはsitemap.xmlの場所を伝えます。
最後にsitemapの書き方について解説します。
クローラーにサイトマップの場所を伝えることは、クローラーに効率よくサイトをクローリングしてもらえるため、クローラー最適化に繋がります。
書き方は簡単で、以下の文章になります。
Sitemap:URL/sitemap.xml
すべてを組み合わせた例も記載しておきます。
User-agent:*
Disallow:/○○
User-agent:
Disallow:/〇〇/××.html
Sitemap:URL/sitemap.xml
User-agentとDisallowがセットで、1行空けてSitemapを書くことが望ましいです。
robots.txtの設置方法について

文章がすべて完成しましたら、ここからは設置方法について解説してきます。
テキストファイルで作成して頂いたと思いますが、まずは「UTF-8」で保存してください。
その際、ファイル名を「robots.txt」として保存します。
作成したファイルは、一番上の階層である「ルートディレクトリ」に設置してください。
ここまでで終わりになります。
意外と簡単だったのではないでしょうか。
正しい場所に設置されているかを確認するには、GSCのrobots.txtテスターをご利用ください。
よくある間違いや注意点
ここからは、よくある間違いや注意点について解説していきます。
robot.txtと表記ミスしてしまう。
→robots.txtですので、間違えないようにしましょう。
すべてのクローラーが指示通りに動くとは限らない。
→robots.txtを無視してクロールするクローラーもあります。
その場合は、「.htaccess」を使いましょう!
人間のアクセスは拒否できません
→あくまでクローラーを最適化するための対策です。
ユーザーをブロックしたいときはページにパスワードをつけましょう。
設置場所は一番上の階層である「ルートディレクトリ」に設置しましょう
→下層のディレクトリでは、クローラーに認識されない恐れがあります。
robots txt noindexの違い

SEOについて勉強している方なら疑問に感じるかもしれませんが、robots.txtとnoindexはどちらもクローラーにクロールされなくなるところが似ていますね。
robots.txtとnoindexの使い方について説明していきます。
まず、noindexを知らない方は以下記事に説明が書いてありますので参考にしてください。
URL:noindexとnofollowって何が違うの?SEOの効果も解説します
簡単に言うと、noindexはクローラーがページのクロールをしなくなり、検索結果に表示されなくなります。
では、どのように使い分けていくのかというとディレクトリ単位でクローラーをブロックしたい時がrobots.txtで検索エンジンにインデックスされず検索結果に表示されたくない場合はnoindexを使うことをおすすめします。
ただし、robots.txtはインデックスされてしまうのでご注意ください。
さらに、robots.txtとnoindexを両方使っているページがある場合は注意が必要です。
それは、noindexを設置しているのにも関わらず、検索結果に表示されている可能性があります。
理由としては、robots.txtでクローラーをブロックしているため、クローラーがnoindexを読み取れない状態になっているからです。
以上の点にも気をつけながら使用しましょう。
まとめ
robots.txtについて理解できましたでしょうか。
僕も最初は難しそうと感じていたのですが、実際にやってみると簡単でしたのでSEO対策を考えている方は、一度試してみてはいかがでしょうか。
弊社でもSEOの内部分析などを行っておりますので、質問があるかたはご連絡お待ちしております。
【編集担当:片岡】









